GPU:从游戏之友到权力之杖

陈永伟 / 文
近日,AI 算力新秀 CoreWeave 在自己的推特上分享了一则消息:该公司刚刚通过抵押英伟达 H100GPU 的方式获得了 23 亿美元的融资,将用这笔钱来购买更多的 H100GPU,以便在年底前再建立 10 个新数据中心。
一位供职于国内某互联网大厂的朋友在转发该消息后评论道:" 以前只听说过地产公司通过抵押房子来拿贷款,然后用贷来的钱继续盖房子。这种抵押 GPU 借钱,再拿借来的钱继续买 GPU 的做法倒是第一次看到。"
一般来说,同样的一件电子产品,年末时的价格会比年初低上一大截。所以几乎不会有人购买电子产品来进行保值,金融机构也很少会愿意接受电子产品作为抵押品。然而,这些经验在 GPU 面前失灵了。今时今日,似乎整个市场都在争抢 GPU,在 eBay 平台上,英伟达 H100GPU 芯片的价格已经被炒到了每张 4.5 万美元,而在两三个月前,它的价格还是在 3.6 万美元左右。
GPU 究竟是什么?为什么在 AI 时代,GPU 会成为人们竞相争抢的硬通货?它的价值来自哪里?又能保持多长的时间?在 GPU 硬通货化的背后,又存在着什么更深的隐喻?且让我们一一说来。
GPU 的由来
大家知道,GPU 是英文 " 图形处理器 "(graphicprocessingunit)的缩写。从这个名字就不难知道,GPU 原本并不是用来执行 AI 相关的任务,而是用来处理图形的。
从上世纪 80 年代开始,随着计算机辅助应用(CAD)、地理信息系统(GIS)等技术的发展,用计算机处理图形的需求开始出现增长。尤其是电子游戏行业的异军突起,更是为计算机图形处理培养了庞大的用户群体。然而,作为计算机处理核心的元件 CPU 在处理图形时效率并不高,这就导致了专业处理图形任务的计算元件的出现。
1983 年,《计算机世界》(ComputerWorld)杂志上刊登的一篇介绍 Tek-tronix 的图形终端的文章里首先出现了 GPU 一词。但是,此 GPU 非彼 GPU,它的全称是 graphicprocessorunit。这一类所谓的 GPU 虽然能够处理 2D 图像,但由于当时还缺乏光影转换(trans-formandlighting,简称 T&L)组件,因而它们还无法独立处理 3D 图形,必须搭配 CPU 使用。直到 1990 年代,图形处理元件加入了 T&L 组件,现在人们所熟悉的 GPU 才正式出现。
关于究竟谁才是现在意义上 GPU 的发明者,业界一直存在着争议。一种观点认为,GPU 的发明权应该归于美国硅图公司(SiliconGraphics,简称 SGI)。1996 年,SGI 推出了可以实现硬件 T&L 的图形处理器,已经具有了现在人们认为的 GPU 的主要功能。不过,由于它主要是被用在任天堂的主机上,所以很多人并不愿意承认它是真正的 GPU。另一种观点则认为,第一块 GPU 是由一家名为 3Dlabs 的英国公司推出的。1997 年时,它在一块双芯片处理器中加入了带有 T&L 功能的引擎,并将这块处理器冠以了 " 几何处理器 "(GeometryPro-cessorUnit,简称也是 GPU)的名字。然而,由于 3Dlabs 专注于 CAD 的狭小市场,影响并不大,因而将其认为是 GPU 发明者的人也不多。
相比于 SGI 和 3Dlabs,一个认可度更高的 GPU 发明者是英伟达。在上世纪 90 年代的半导体市场上,英伟达其实算是一个后来者。当时,这个市场上的基本格局是 AMD 和英特尔两大巨头对峙,而它们争夺的焦点是 CPU。在那几年中,英特尔的奔腾系列 CPU 和 AMD 的 Am386、Am486 系列 CPU 可谓是你方唱罢我登场,战得不亦乐乎,其他企业只能坐看神仙打架。
1993 年,就在整个市场都认为很难在巨头霸占的市场中抢到机会时,供职于 LSILogic 的黄仁勋却选择了辞职下海,创立了英伟达。不过,黄仁勋看好的并不是 CPU,而是图形加速卡。在当时看来,这似乎是一个非常冷门的业务。虽然随着 PC 和游戏机的普及,不少人认识到了图形处理的重要性,但其中的大部分人认为这个任务应该由 CPU 而不是专门的图形处理硬件来完成。
但黄仁勋并不这么认为,他坚持看好图形处理硬件的未来。在很大程度上,他的这个判断来自于对当时游戏行业的观察。1993 年,一款名为《德军总部 3D》(Wolfstein3D)的游戏横空出世,引发了市场对 3D 游戏的极大兴趣。但事实上,《德军总部 3D》并不是真 3D,它只是用 2D 贴图伪装出了 3D 效果。在黄仁勋看来,既然单独的 CPU 不足以支持真 3D 游戏,那么要实现它们就只能采用辅助的加速硬件。当然,虽然当时看好硬件加速市场潜力的人不多,但也不只黄仁勋一人。比如,英伟达早期最重要的竞争者 3dfx 公司也很早押注了这个市场,并一度凭借着其率先推出的巫毒(Voodoo)加速卡雄霸全球市场。
应该说,黄仁勋运气确实不错,在创业初期就收到了日本游戏机公司世嘉的芯片研发订单,并得到了 700 万美元资金支持。但这种运气并没有持续多久,由于他在 3D 图像技术上选择的失误,没能兼容微软新制定的 DirectX 标准,导致了初代产品 NV1 出师不利,销量惨淡。
在经过一番调整后,英伟达终于步入了正轨。靠着世嘉公司支付的研发费用,英伟达开发出了 Riva128。坦白讲,单论性能,Riva128 并不如巫毒,但 3dfx 却犯了一个致命的错误——坚持自己的开发工具 GlideAPI,拒绝使用 DirectX。而英伟达则及时吸取教训,选择了拥抱微软、拥抱 DirectX。很显然,在微软统治 PC 系统的时代,这个策略是十分明智的,Riva128 也因此而大卖。
1998 年,英伟达与台积电达成合作,开始使用 " 无工厂 "(Fabless)模式。之后,英伟达只负责芯片的设计和销售,生产则完全交托给台积电来代工。通过这种模式,英伟达得以轻装上阵,将更多的精力投放到研发和市场研究中,从而推出了一系列爆款产品。利用这些产品,英伟达终于在图形加速市场上站稳了脚跟。
不过,黄仁勋的野心当然不止于此。在他看来,图形加速硬件不应该只是 CPU 的助手,应该有自己的独立角色。在这种理念的指导下,英伟达于 1999 年推出了它的 GeForce256 显卡。这款显卡不仅将 T&L 功能整合到了其中,实现了独立于 CPU 的 T&L 处理,集成了立方环境材质贴图、顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素、256 位渲染引擎等先进技术,还同时设计了可编程加速功能。在这些技术特质的加持之下,GeForce256 对一些高端 3D 游戏的支持能力要远胜于当时流行的 3D 图形加速卡,面世后一炮而红,迅速成为了广大发烧友钟爱的游戏神器。英伟达也趁热打铁,利用广告攻势,顺势将 " 具有集成 T&L、三角形设置 / 裁剪和渲染引擎,能够每秒至少处理 1000 万个多边形的单芯片处理器 " 定义为了 GPU ——如果严格按照这个定义,那么英伟达就确实是 GPU 的发明者了。
英伟达迅速成为了这个市场上的胜利者和引领者。2000 年,它更是将最主要的竞争对手 3dfx 直接收购,进一步稳固了自己的市场霸主地位。所谓历史是由胜利者书写的,时至今日,当我们在搜索引擎上搜索谁是 GPU 的发明者时,英伟达就成了默认的答案。
从游戏之友到 AI 神器
那么,GPU 又是怎么从一款游戏神器变成 AI 神器的呢?在对这个问题进行说明前,我们需要先对 GPU 的结构进行一些简单的介绍。
从总体上看,无论是 CPU 还是 GPU,都包括运算器(ArithmeticandLogicUnit,简称 ALU)、控制单元(ControlUnit,简称 CL)、高速缓存器(Cache)和动态随机存取存储器(DRAM)。但是,这些成分在两者中的构成比例是不同的。在 CPU 当中,控制单元和存储单元占的比例很大,而作为计算单位的 ALU 比例则很小;而在 GPU 当中则正好相反。
这种结构上的差异决定了 CPU 和 GPU 功能上的区别。由于 CPU 在控制和存储的能力上比较强,因此就能进行比较复杂的计算,不过可以同时执行的线程很少。而 GPU 则相反,大量的计算单位让它可以同时执行多线程的任务,但每一个任务都比较简单。打个比喻,CPU 是一个精通数学的博士,微积分、线性代数样样都会,但尽管如此,让他做一万道四则运算也很难;而 GPU 呢,则是一群只会四则运算的小学生,虽然他们不会微积分和线性代数,但人多力量大,如果一起开干,一万道四则运算分分钟就能搞定。
由于在图形处理的过程中会涉及很多不同色彩单元的图形和色彩的变换,所以 GPU 的特质就让它先天地适合被作为图形处理的硬件使用。而当深度学习兴起之后,人工智能专家们很快就发现,GPU 也很适合用来训练神经和应用网络模型。因为在深度学习模型中,最主要的运算就是矩阵运算和卷积,而这些运算从根本上都可以分解为简单的加法和乘法。如此一来,GPU 就找到了新的 " 就业 " 空间,开始被广泛地应用于人工智能,摇身一变,从游戏神器变成了 AI 神器。
对于英伟达这个 GPU 市场的王者,AI 领域的上述动向简直是为它送来了一块天上掉下的馅饼。它也顺势抓住了这个机会。2007 年,英伟达提出了 GPGPU,即 " 通用目的 GPU"(GeneralPurposeGPU)架构,将原本专用于图形处理的 GPU 改造成了更适合 AI 运算的 GPU。与此同时,英伟达还推出了 GPGPU 的计算统一架构(ComputeU-nifiedDeviceArchitecture,CUDA)平台,允许程序员使用类 C 语言编写 GPU 的并行计算代码,并且提供了大量的库函数和工具来帮助优化 GPU 计算。通过这些努力,英伟达成功将 GPU 能处理的问题由图形扩展到了通用计算领域,由此在市场上抢得了先机,率先从游戏领域的硬件霸主转型成了 AI 领域的 " 军火商 "。
各大 AI 巨头为抢占大模型市场抢破头时,这位 " 军火商 " 却坐收渔人之利,成为了这场大战最大的赢家——不仅赚得盆满钵满,让自己的市值突破了万亿美元大关,还凭借着其对 GPU 进行分配的权力,在某种程度上成为了左右 AI 大战最终走向的幕后之手。
从 AI 神器到硬通货
现在我们回到本文开头的问题:为什么 GPU 并没有遵循一般半导体产品的价格下降规律,反而成为了一件硬通货?
在市场经济的条件下,可以让某种商品的价格保持高昂且坚挺的原因只有一个,那就是需求超过了供给。要理解 GPU 为何能够成为硬通货,就必须对其供求状况有所了解。
1、GPU 的需求状况
什么人在购买 GPU 呢?关于这个问题,马斯克曾给出过一个回答:" 在现在这个时间点,似乎所有人和他们的狗都在到处找 GPU。" 马斯克的这个回答当然是带有调侃的,但是整个 AI 圈确实都在为 GPU 而疯狂。
最近在社交新闻网站 Raddit 上热传的一篇文章曾对几个大公司的 GPU 需求量做过一个统计。根据这篇文章,OpenAI 在训练 GPT-4 时曾使用了 10000 到 25000 张英伟达 A100GPU;脸书在训练 AI 时使用了大约 21000 张 A100;特斯拉使用了约 7000 张 A100;Midjourney 的开发者 StabilityAI 大约使用了 5000 张 A100。此外,阿联酋阿布扎比技术创新研究所开发的 Falcon-40B 用了 384 张 A100 进行训练;AI 初创公司 Inflection 则正在使用 3500 张 H100GPU 来训练性能足以匹敌 GPT-3.5 的大模型。而根据马斯克的爆料,OpenAI 正在训练的 GPT-5 所使用的 H100GPU 可能达到了 3 万到 5 万张。除此之外,还有众多初创企业也都需要 GPU,需求量从几百张到几千张不等。所有这些需求加总在一起,就构成了十分庞大的数字。
这里需要说明的是,在 GPU 市场上,不同型号的 GPU 的需求差别非常大。目前,市场上最受欢迎的 GPU 就是英伟达的 H100。根据英伟达方面的介绍,这款专门为人工智能设计的 GPU 芯片采用了新一代的 Hopper 架构,拥有 800 亿个晶体管,无论是在深度学习模型的训练还是推理方面,都具有十分强大的能力。在各种第三方的测试当中,H100 也取得了非常好的成绩。例如,在近期举行的一次 MLPerfAI 测试中,英伟达 H100 集群一举在全部八个项目中都获得了第一,仅用 11 分钟就完成了一遍 GPT-3 的训练,用 8 秒就完成了一遍 BERT 模型的训练。
得益于 H100 的优良性能,所以几乎所有 AI 企业都对其虎视眈眈。根据网上热传的一个估计:OpenAI 可能需要 5 万张 H100;脸书可能需要 2.5 万张;Inflection 需要 2.2 万张;微软的 Azure 云、谷歌云、亚马逊的 AWS,以及 Oracle 这四大云服务商可能各需要 3 万张;Lambda、CoreWeave 以及其他私有云可能总共需要 10 万张;Anthropic、Helsing、Mistral、Character 等企业可能各需要 1 万张——将上面这些需求加总在一起,H100 的总需求量就超过了 43 万张。需要指出的是,上述估计数字还没有包括中国的大型科技企业,以及包括 JP 摩根在内的众多金融企业的需求。如果将这些企业的需求量考虑在内,H100 的需求量将更是惊人。
或许有人会问,同样是 GPU,为什么 H100 会要比其他型号的 GPU,比如 A100 更受欢迎呢?这其实既是一个技术问题,也是一个经济问题。总体上讲,尽管同为 GPU,但是不同型号的 GPU 之间的主要职能是不同的。大致上讲,在 AI 领域,GPU 的用途主要有两种:一是推理(inference),即用训练好的模型生成我们需要的结果和内容;二是训练(training),即利用样本数据来训练 AI 模型。由于任务不同,所以在设计过程中必须安排不同的架构来对它们进行支持。一般而言,推理过程通常需要高效的计算能力和低延迟的响应速度,因此推理芯片的设计注重高效的计算单元和能耗控制;而训练过程则需要更高的计算能力和存储能力,因此训练芯片的设计注重高度并行化和大规模存储。
得益于更为优秀的架构设计,H100 无论是在推理能力还是训练能力上都要比 A100 更优。测试结果表明,它的 16 位推理速度大约是 A100 的 3.5 倍,16 位训练速度则大约是 A100 的 2.3 倍。而从成本上看,H100 大约是 A100 的 1.5 到 2 倍。由此可见,虽然 H100 的价格要比 A100 更贵,但从性价比看,H100 则具有更大的优势。
这里尤其需要指出的是,当 Chat-GPT 的爆火之后,大批企业都投入了大模型的开发。对于这些企业而言,能够更早地开发出品质优良的大模型就能为自己在竞争中获得更为有利的位置,这就激发了它们对可以以更快速度训练模型的工具的渴望。
2、GPU 的供应状况
既然现在价格已经被炒上了天,那么供应商就应该抓住这个机会卖卖卖吧。但有意思的是,各大 GPU 供应商迟迟不增加供给,逼得一些 AI 企业甚至不得不到二手市场去收购旧的 GPU。非不愿也,实不能也。
对于包括 GPU 在内的半导体产品而言,整个供应链可以分为三段:上游主要是指 EDA、IP 授权以及 GPU 芯片设计,中游主要是指 GPU 的制造和封装测试,下游主要是集成商和终端销售。其中,现在 GPU 卡口最严重的部分就出在供应链的中游。
众所周知,芯片的生产对于工艺的要求非常高,因此符合生产条件的制造商很少。以英伟达的 H100 为例,正如我们前面提到的,在英伟达采用了 " 无工厂 " 模式之后,其制造就全部委托给了台积电。但是,即使是对台积电而言,也只有 N5、N5P、N4 和 N4P 四个制程节点(注:制程节点指的是电路铸造的制程工艺节点。通常以纳米来衡量,例如 N5 指的就是 5 纳米制程节点。制程节点越小 , 在一块晶圆上可以制造的集成电路就越多。)可以用来进行 H100 的制造。而由于台积电的制作工艺突出,所以苹果、高通等公司都在委托其进行代工,因而英伟达就不得不需要和这些公司一起共用以上制程节点。除此之外,在封装环节,台积电也面临着产能的限制。这些因素加在一起,就导致了 H100 在供应链的中游面临着非常紧的瓶颈。
与此同时,还需要注意的一点是,GPU 的组件供应也在一定程度上制约着它的供应。仍以 H100 为例,其使用的关键组件高带宽存储器(HighBandwidthMemory,简称 HBM)就面临着很严重的供应限制。目前,英伟达在 H100 上使用的 HBM 几乎都来自于韩国企业 SK 海力士半导体公司(SKHynix)。然而,SK 海力士生产 HBM 的能力是有限的,这就对 H100 的产量构成了直接的限制。有传闻说英伟达可能从三星和美光采购一部分 HBM,但这两家企业的产能依然是有限的,因此扩大采购范围究竟可以在多大程度上缓解 HBM 的紧缺依然是一个问题。
综合以上分析,我们可以看到,虽然面临着 GPU 需求的暴涨,但由于供应链的制约,GPU 的供应量很难在短期内出现重大提升。目前看来,由生成式 AI 所带动的算力需求增长还会持续较长的一段时间,因而至少在这段时间内,GPU 的供不应求还会继续存在。在需求定律的作用之下,这就导致了 GPU 这种半导体产品出现了十分反常的价格持续上升。因此,在融资当中,它也就得以扮演起了抵押品的角色。
从财富之源到权力之杖
当人们津津乐道于 GPU 竟然可以成为硬通货,在金融市场上作为抵押品的时候,很可能忽略了另外一层更深的隐喻,即随着 GPU 在 AI 时代作用的日益突出,它似乎正在成为 AI 领域的权力之源。
7 月 25 日,微软公布了它 2023 财年第四季度的财报。得益于和 OpenAI 的合作,微软的云业务在本财季出现了大幅的增长,带动了公司营收状况的显著改善。与去年相比,其营收同比增长了 8%,净利润的同比涨幅更是达到了 20%。在展示自己所取得的骄人成绩的同时,微软也在财报中提示了一些潜在的风险,其中之一就是 GPU 风险。微软指出,GPU 已经成为了支撑其云业务迅速增长的关键原材料,如果 GPU 的供应不能保证,则其服务质量可能会受到很大影响。
为了缓解对 GPU 的渴求,微软可谓是不遗余力。一方面,它直接向英伟达方面示好,要求采购更多的 GPU。另一方面,它也想了一些迂回的方法。比如,在不久之前,它就和 CoreWeave ——也就是本文开头提到的那家抵押 H100 来借钱买 H100 的算力提供商达成了协议,约定将在未来几年内持续向后者提供金额数十亿的投资,一起建设云计算的基础设施。其原因在于 CoreWeave 和英伟达关系甚密,在不久前的 B 轮融资中,就得到了英伟达的投资。凭借着这层关系,英伟达方面许诺会优先对 CoreWeave 提供 GPU 的供应。因此,对于微软来说,投资 CoreWeave 就是和英伟达套了近乎,从而有机会让它得到更多的 H100 和 A100 的使用权。看看微软现在这番良苦的用心,再联想英伟达创业之初为求生存不得不屈服于微软创立的标准,真不禁让人感叹三十年河东,三十年河西。
当然,我们还可以举出更多的 GPU 供应商操控 AI 之战的案例。一个典型的例子是我们前面起到过的 Inflection。这家由 DeepMind 联合创始人穆斯塔法 · 苏莱曼(MustafaSuleyman)创办并担任 CEO 的公司最近可谓风头正劲。和其他大模型公司不同,Inflection 并不想创造无所不能的通用人工智能(AGI),而是将注意力集中在了个人智能(PI)领域。它的主要产品——名为 Pi 的聊天机器人功能也很单一,目前只有聊天。很显然,在目前林立的 AI 模型中,这款产品并不出众。然而,就是这样一家看似平平无奇的公司,其估值却达到了 40 亿美元。除了它拥有的宝贵智力资源外,一个重要的原因就是 GPU。不久前,Inflection 公开宣布,它将打造一个拥有 2.2 万块 H100 芯片的超级计算集群,以支持新一代 AI 大模型的训练和部署。这个集群的集成数量已经完全超越了脸书于 5 月宣布的计划。
Inflection 是怎么做到的呢?只要我们看一下它的投资人,答案就立即揭晓了。是的,在它的投资人中,就有英伟达。另外值得一提的是,Inflection 在打造这个集群的过程中,还有一个重要的合作者—— CoreWeave。而正如我们已经看到的,它也是英伟达的利益共同体。由此可知,Inflection 得以爆火的背后,英伟达以及它手中的 GPU 应该起了关键的作用。
记得今年 3 月,各大生成式 AI 公司激战正酣的时候,曾有一位记者来采访我,她问:" 依您看来,这场 AI 大战的最后赢家会是谁?微软,谷歌,还是 OpenAI?" 我当时的回答是:" 我不知道它们当中谁会赢,但最后的赢家里一定有英伟达!" 现在看来,这个回答是完全正确的。不过,如果现在她再问我这个问题,我会在答案上再加一句:或许,它还能用 GPU 投票,决定谁会是赢家。

用户对喜马拉雅的“一台设备一充值”的抱怨引发了网友的吐槽,认为这是一种花式割韭菜行为。
科技热搜 喜马拉雅 天猫精灵 手表 设备 韭菜 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-08-07

“遥遥领先”,一个华为热梗的走红
科技热搜 华为 芯片 余承东 华为mate 雷蒙 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-09-29

华为 Mate 60 Pro DXOMARK 影像测试结果出炉:总分157,位列排行榜第 1 名
科技热搜 华为mate google pixel oppo find x iphone 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-11-17

《繁花》:A先生最后一集终于露脸,为何是宝总的模样?
娱乐热点 导演 a股 李产 股市 陈真 新闻 资讯 直播 视频 美图 社区 本地 热点 2024-01-18

韩国女团大尺度造型惹争议,穿着令人费解,成员还有中国人
娱乐热点 造型 韩国 尺度 中国人 穿着 新闻 资讯 直播 视频 美图 社区 本地 热点 2024-02-04
 曾被卖出19万美元高价!这台初代iPhone太猛了
曾被卖出19万美元高价!这台初代iPhone太猛了
热门赛事

苹果首次允许欧盟用户从网站安装应用/雷军称对汽车价格战做好准备/微博上线热搜投诉入口
科技热搜 2024-03-13
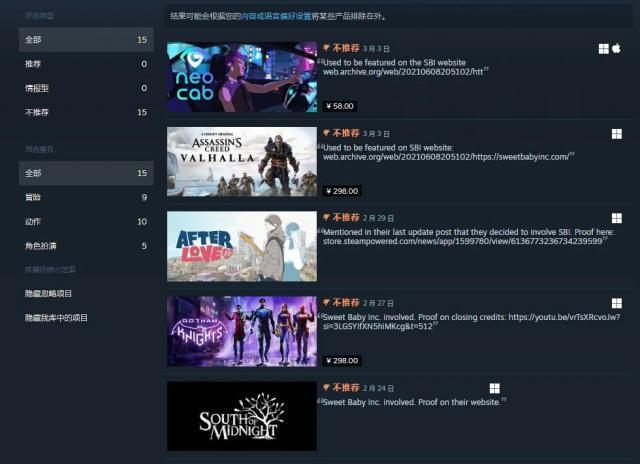
在游戏里搞政治正确的幕后黑手,快被外国网友冲烂了。
科技热搜 2024-03-13
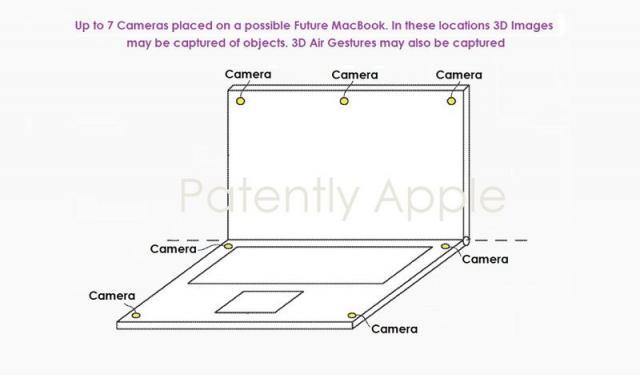
苹果 MacBook 新专利获批:可录制3D 图像/视频、追踪空中手势
科技热搜 2024-03-13
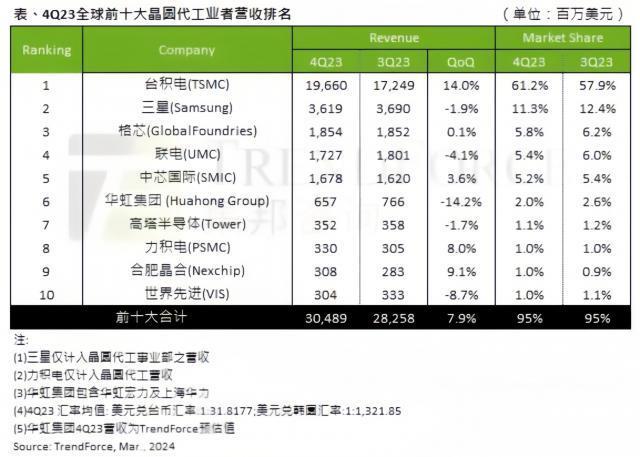
芯片代工营收排行榜公布:台积电独占六成,狂揽近200亿美元
科技热搜 2024-03-13
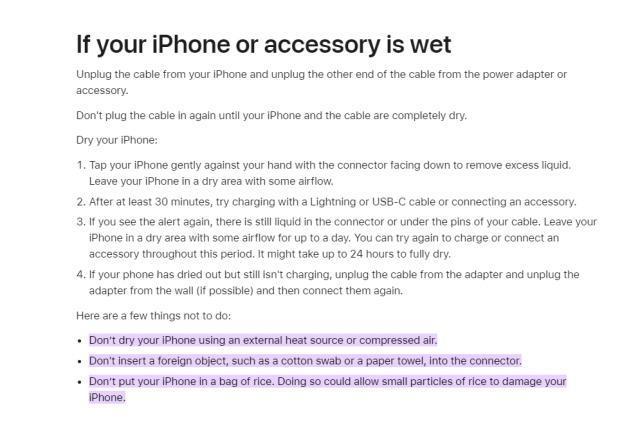
手机进水放米缸?苹果说这招没用。
科技热搜 2024-03-13

TikTok以“美式”反击“美式”
科技热搜 2024-03-13

消息称暴雪国服回归将在一个月内官宣,网易雷火营销/互娱运营
科技热搜 2024-03-13

从“放生”农夫山泉开始,这事算是彻底成互联网闹剧了。
科技热搜 2024-03-13
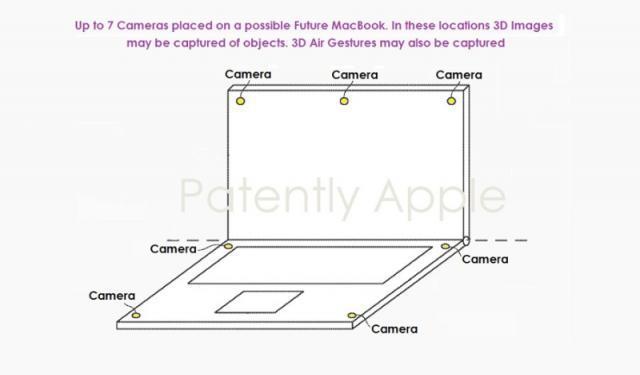
苹果获得适用于折叠设备和MacBook的摄像头系统专利
科技热搜 2024-03-13

消息称现代汽车将研发5纳米车用半导体,有望由三星、台积电代工
科技热搜 2024-03-13