英伟达最大的风险,在很少人关注的角落里

题图来自:视觉中国
今年的英伟达确实 " 猛 ",不遗余力拼算力似乎已经成了科技巨头们的共识,部分原因在于,不少大模型都以对算力需求较高的 Transformer 为架构。而如果在不断迭代的过程中,Transformer 逐步被对算力需求少的架构取代,这是否也将成为英伟达的 " 潜在风险 "?
投资了 OpenAI 劲敌 Cohere 的著名风险投资家、Radical Ventures 合伙人 Rob Toews,在 9 月 3 日发布的专栏文章指出,Transformer 在训练时支持并行化,与 GPU 的 " 爆火 " 时间点吻合。GPU 拥有更多流处理器,适合对密集数据进行并行处理和并发计算,非常适合且支持基于 Transformer 的计算工作流负载。
毫无疑问,Transformer 的架构非常强大,彻底改变了 AI 界,但缺点也明显,当文章长度变长,计算复杂度就变得非常高。同时,随着模型规模不断扩大,所需计算量呈指数级增加,这两点都让 Transformer 的算力需求激增。
Toews 指出,为了弥补 Transformer 存在的问题,包括 Hyena、Monarch Mixer、BiGS、MEGA 等提出了用 Subquadratic 方法来降低运算复杂度,减少算力需求。
Toews 直言,尽管这些架构距离挑战 Transformer 的 " 王座 " 仍有较大差距,但不可否认的是,AI 发展过程中新鲜的事物接连出现,在不断更新换代的过程中,或许没有什么是永远屹立不倒的。
当算力需求激增之时,从某种程度上说,谁手握英伟达 GPU,谁就掌握了 AI 时代最硬的 " 硬通货 "。而如果在未来 Transformer 被对算力需求不高的架构取代,那对最大 " 卖铲人 " 英伟达来说可能不是一件好事。
Transformer 的庞大计算成本
2017 年 6 月 12 日,《Attention is All You Need》论文横空出世,让大模型领域变天的 Transformer 架构出现了。截至 9 月 4 日,Transformer 诞生 6 年,而这篇论文被引用高达 87345 次。

分析指出,基于 Transformer 不断扩展的大模型们,都是以处理性能和功耗方面的高昂成本为代价。因此,虽然人工智能的潜力可能是无限的,但物理和成本却是有限的。
为什么 Transformer 对算力的要求如此之高?Toews 解释称,主要有以下两个原因:1. 注意力(attention)机制的计算复杂度;2. 越发庞大的模型规模。
Transformer 的基本原理是使用自注意力机制来捕获序列数据中的依赖关系,无论它们的距离有多远。
注意力机制需要将序列中每个词与其他所有词进行配对比较,这导致运算量随序列长度的平方增长,即计算复杂度为 O ( n2 ) 。这种平方级复杂度使得随着文本长度增加,所需计算成本急剧上升。
与此同时,Transformer 架构可以更好地扩展大模型,所以研究者不断基于 Transformer 训练更大规模的模型。目前主流的语言模型参数量达到了数百亿级甚至万亿级,需要大量算力支持。随着模型规模的扩大,所需算力呈指数级上涨。
谷歌母公司 Alphabet 首席财务官 Ruth Porat 在财报电话会上表示,由于需要投资 AI 基础设施,资本支出将比去年的创纪录水平 " 略高 "。
微软最新报告显示,该公司季度资本支出超出预期,首席财务官 Amy Hood 称原因为加大 AI 基础设施建设。
微软在今年年初又向 OpenAI 砸了 100 亿美元,为了支撑起大语言模型训练所需的庞大计算资源费用。成立仅 18 个月的初创公司 Inflection 也融资超过 10 亿美元用于构建 GPU 集群,以训练其大语言模型。
英伟达 GPU 在市场的 " 哄抢 " 中陷入产能瓶颈。最新的 H100 芯片早已全部卖空,现在下单要等 2024 年第一季度甚至第二季度才能排上队。
Toews 指出,上述种种都不难看出,基于 Transformer 的模型对计算资源的需求之大,以至于当前的人工智能热潮引发了全球 GPU 供应短缺,硬件制造商无法跟上激增的需求。
Transformer 面临的难题
同时,Toews 指出,Transformer 处理的句子长度受限,已有的方法大多使用截断的方式,这会导致信息损失,因此如何实现长文本的预训练是目前的一大难题。
而这场 AI 军备竞赛注定还将持续下去,如果 OpenAI、Anthropic 或任何其他公司继续使用 Transformer 架构,那么它们模型的文本序列长度会受限。
Toews 指出,人们已经进行了各种尝试更新 Transformer 架构,仍然使用注意力机制,但能够更好地处理长序列。然而,这些改进后的 Transformer 架构(如 Longformer、Reformer、Performer、Linformer 和 Big Bird)通常会牺牲部分性能,因此未能获得采用。
Toews 强调,没有一样事物会是完美的,历史的发展也不会停下脚步,尽管 Transformer 现在占据绝对的优势地位,但它也并非没有缺点,而这些缺点为新的架构打开了大门。
" 王位 " 挑战者出现了?
Toews 认为,现在寻找可以替代 "Transformer" 的架构成了最有潜力的领域,而其中的一个研究方向是用一种新的函数替代注意力机制。包括 Hyena、Monarch Mixer、BiGS、MEGA 等提出了用 Subquadratic 方法来降低运算复杂度,减少算力需求。
Toews 强调,斯坦福和 Mila 的研究人员提出了一种名为 Hyena 的新架构,具有代替 Transformer 的潜力,它是一种无注意力、卷积架构,可以匹配注意力模型的质量,同时可以降低计算成本。在二次多项式 NLP 任务上表现出色:
据称,Hyena 可达到与 GPT-4 同等的准确性,但使用的算力比后者减少了 100 倍。这是第一个能够在总 FLOPS 减少 20% 的情况下与 GPT 质量相匹配的无注意力架构,具有成为图像分类的通用深度学习运算符的潜力。
Toews 表示,需要注意的是,最初的 Hyena 研究是在相对小的规模下进行的。最大的 Hyena 模型具有 13 亿个参数,而 GPT-3 有 1750 亿个参数,GPT-4 据说达到 1.8 万亿个参数。因此针对 Hyena 架构的一个关键测试将是,在将其扩展到当前 Transformer 规模的情况下,它是否能继续表现出强大的性能和效率提升。
Toews 认为,液态神经网络是另一个具有取代 "Transformer" 潜力的架构。麻省理工学院的两名研究人员从微小的秀丽隐杆线虫(Caenorhabditis elegans)中汲取灵感,创造了所谓的 " 液态神经网络 " (liquid neural networks)。
据称,液态神经网络不仅速度更快,而且异常稳定,这意味着系统可以处理大量的输入而不至于失控。
Toews 认为,这种较小的架构意味着液态神经网络比 Transformer 更加透明,且更易于人类理解:
毕竟,对于人类来说,更容易解释具有 253 个连接的网络发生了什么,而不是拥有 1750 亿个连接的网络。
当架构不断改进,逐渐减少了对算力的依赖,是否也意味着会对未来英伟达的营收产生影响?
本文来自微信公众号:华尔街见闻 (ID:wallstreetcn),作者:葛佳明

用户对喜马拉雅的“一台设备一充值”的抱怨引发了网友的吐槽,认为这是一种花式割韭菜行为。
科技热搜 喜马拉雅 天猫精灵 手表 设备 韭菜 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-08-07

“遥遥领先”,一个华为热梗的走红
科技热搜 华为 芯片 余承东 华为mate 雷蒙 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-09-29

华为 Mate 60 Pro DXOMARK 影像测试结果出炉:总分157,位列排行榜第 1 名
科技热搜 华为mate google pixel oppo find x iphone 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-11-17

《繁花》:A先生最后一集终于露脸,为何是宝总的模样?
娱乐热点 导演 a股 李产 股市 陈真 新闻 资讯 直播 视频 美图 社区 本地 热点 2024-01-18

韩国女团大尺度造型惹争议,穿着令人费解,成员还有中国人
娱乐热点 造型 韩国 尺度 中国人 穿着 新闻 资讯 直播 视频 美图 社区 本地 热点 2024-02-04
 曾被卖出19万美元高价!这台初代iPhone太猛了
曾被卖出19万美元高价!这台初代iPhone太猛了
热门赛事

苹果首次允许欧盟用户从网站安装应用/雷军称对汽车价格战做好准备/微博上线热搜投诉入口
科技热搜 2024-03-13
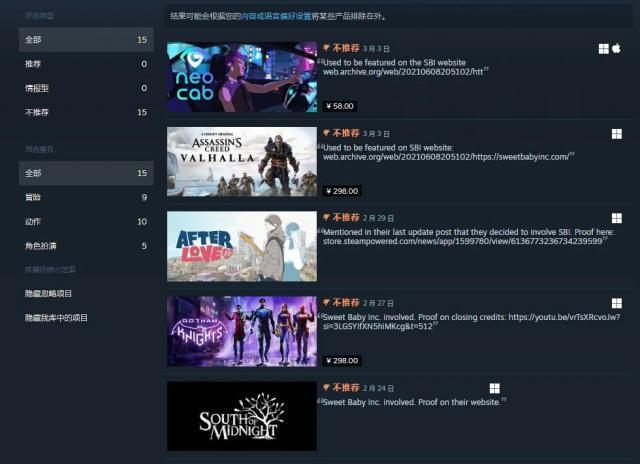
在游戏里搞政治正确的幕后黑手,快被外国网友冲烂了。
科技热搜 2024-03-13
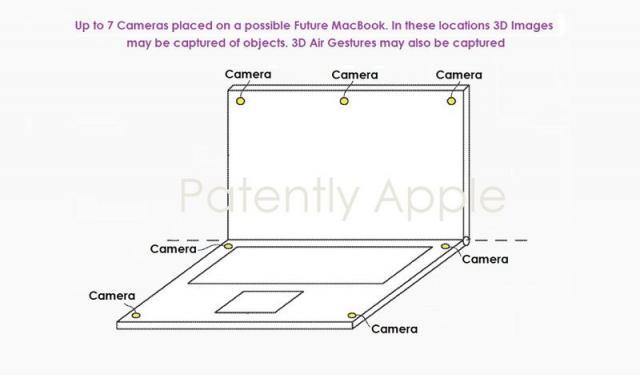
苹果 MacBook 新专利获批:可录制3D 图像/视频、追踪空中手势
科技热搜 2024-03-13
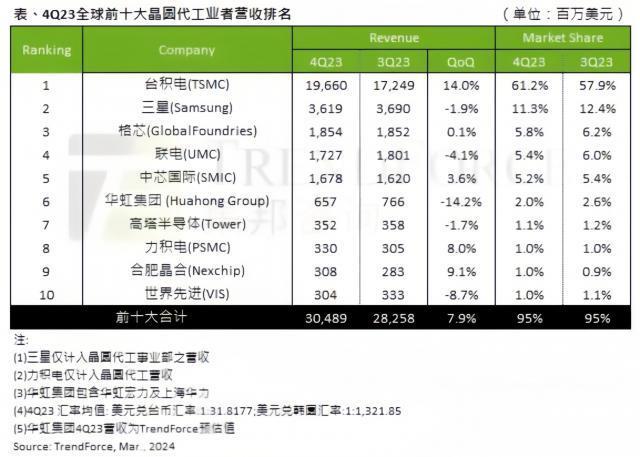
芯片代工营收排行榜公布:台积电独占六成,狂揽近200亿美元
科技热搜 2024-03-13
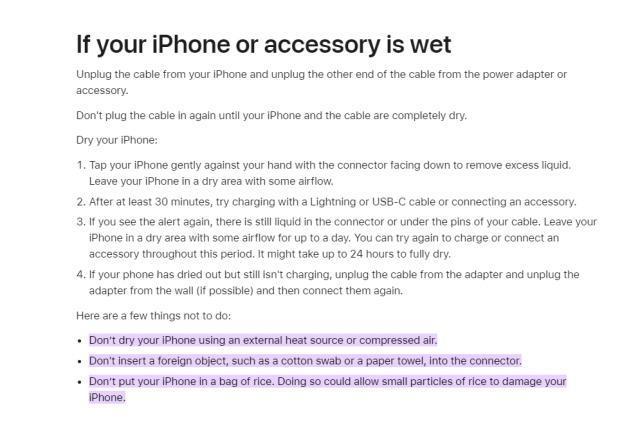
手机进水放米缸?苹果说这招没用。
科技热搜 2024-03-13

TikTok以“美式”反击“美式”
科技热搜 2024-03-13

消息称暴雪国服回归将在一个月内官宣,网易雷火营销/互娱运营
科技热搜 2024-03-13

从“放生”农夫山泉开始,这事算是彻底成互联网闹剧了。
科技热搜 2024-03-13
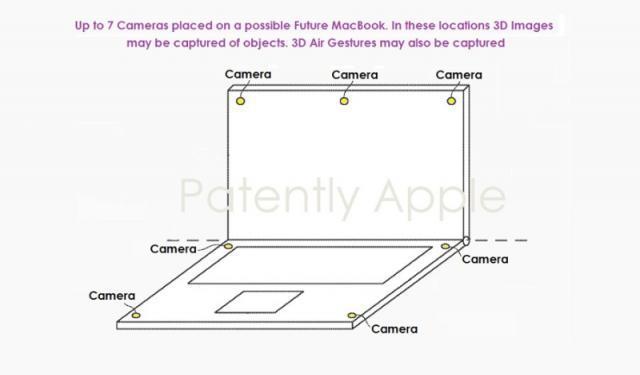
苹果获得适用于折叠设备和MacBook的摄像头系统专利
科技热搜 2024-03-13

消息称现代汽车将研发5纳米车用半导体,有望由三星、台积电代工
科技热搜 2024-03-13