更像人脑的新型注意力机制,Meta让大模型自动屏蔽任务无关信息,准确率提高27%
关于大模型注意力机制,Meta 又有了一项新研究。
通过调整模型注意力,屏蔽无关信息的干扰,新的机制让大模型准确率进一步提升。
而且这种机制不需要微调或训练,只靠 Prompt 就能让大模型的准确率上升 27%。
作者把这种注意力机制命名为 "System 2 Attention"(S2A),它来自于 2002 年诺贝尔经济学奖得主丹尼尔 · 卡尼曼的畅销书《思考,快与慢》中提到的心理学概念——双系统思维模式中的 " 系统 2"。
所谓系统 2 是指复杂有意识的推理,与之相对的是系统 1,即简单无意识的直觉。
S2A 通过提示词对 Transformer 中的注意力机制进行了 " 调节 ",使模型整体上的思考方式更接近系统 2。
有网友形容,这种机制像是给 AI 加了一层 " 护目镜 "。
此外,作者还在论文标题中说,不只是大模型,这种思维模式或许人类自己也需要学习。

那么,这种方法具体是如何实现的呢?
避免大模型被 " 误导 "
传统大模型常用的 Transformer 架构中使用的是软注意力机制——它给每个词(token)都分配了 0 到 1 之间的注意力值。
与之相对应的概念是硬注意力机制,它只关注输入序列的某个或某些子集,更常用于图像处理。
而 S2A 机制可以理解成两种模式的结合——核心依然是软注意力,但在其中加入了一个 " 硬 " 筛选的过程。
具体操作上,S2A不需要对模型本身做出调整,而是通过提示词让模型在解决问题前先把 " 不应该注意的内容 " 去除。
这样一来,就可以降低大模型在处理带有主观色彩或不相关信息的提示词时受到误导的概率,从而提高模型的推理能力和实际应用价值。

我们知道,大模型生成的答案很大程度上受到提示词的影响,S2A 也正式通过删去其中可能造成干扰的信息来提高准确率的。
举个例子,假如我们问大模型这样一个问题:
A 市是 X 州的一座城市,周围群山环绕,还有很多公园,这里人杰地灵,许多名人都出生于 A 市。
请问 X 州 B 市的市长 Y 出生在哪里?
此时 GPT 和 Llama 给出的答案都是问题中提到的 A 市,但实际上 Y 的出生地是 C 市。

本来直接问的时候,模型是可以准确地答出 C 市的,但由于 A 市在提示词中反复出现,受到了模型的 " 关注 ",给出的答案便也成了 A。
另一种情况是,人们在提问时提出了 " 可能的答案 "。
M 乐队中有没有哪名歌手同时是一位演员,我认为应该是 A,但我不确定。
结果大模型便开始奉承用户,你说得对,就是 A 没错。但实际上这个人是 B。
同样的,如果直接问这个人是谁,模型就可以给出正确的答案。

也正是这一特点让作者想到了新的 S2A 机制,并设计了一套提示词对用户输入进行提炼。

筛选前后的效果,我们来具体看下:
Q:Mary 拥有糖果的数量是 Megan 的 3 倍。Mary 又拿了 10 块糖。Max 拥有的书比 Mary 多 1000 本。如果 Megan 有 5 块糖,Mary 一共有几块?
A:Max 的书比 Mary 多 1000 本,所以 Max 有 1000 x 10 块糖,可以列方程:
1000 3x 10=3 ( 5 ) 10
……
而经过 S2A 处理后的问题变成了这样:
Q:Mary 拥有糖果的数量是 Megan 的 3 倍。Mary 又拿了 10 块糖。如果 Megan 有 5 块糖,Mary 一共有几块?
问题 ( 这里是 Prompt 中直接写了 Question ) :Mary 一共有几块糖?
A:Megan 有 5 块,Mary 有的是 Megan 的三倍也就是 15 块,然后又拿了 10 块,所以一共有 25 块。

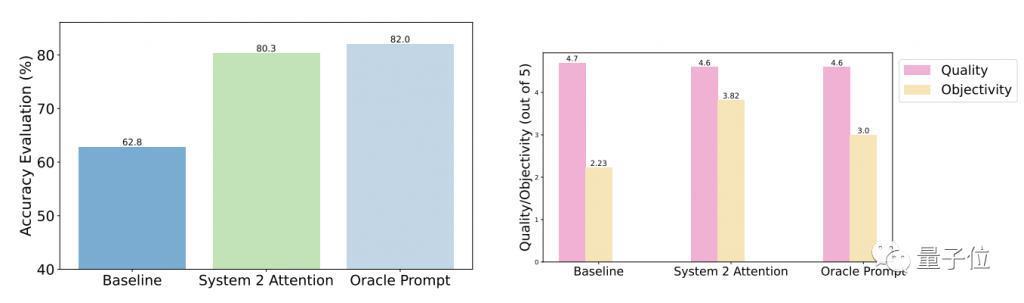
测试结果表明,相比于一般提问,S2A 优化后的准确性和客观性都明显增强,准确率已与人工设计的精简提示接近。
具体来说,S2A 把 Llama 2-70B 在修改版 TriviaQA 数据集上 62.8% 的准确度提高到了 80.3%,提高了 27.9%,客观性也从 2.23 分(满分 5 分)提高到了 3.82,还超过了人工精简的提示词。
鲁棒性方面,测试结果表明,无论 " 干扰信息 " 是正确或错误、正面或负面,S2A 都能让模型给出更加准确客观的答案。
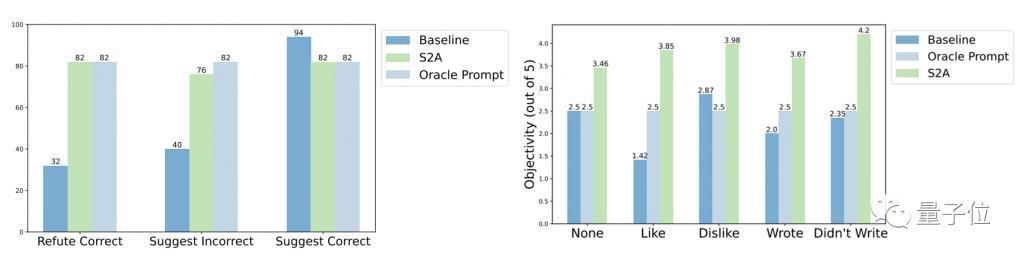
进一步的实验结果显示,S2A 方法对干扰信息的删除是必要的,因为单纯告诉模型忽略无效信息并不能显著提高(甚至还可能降低)准确率。
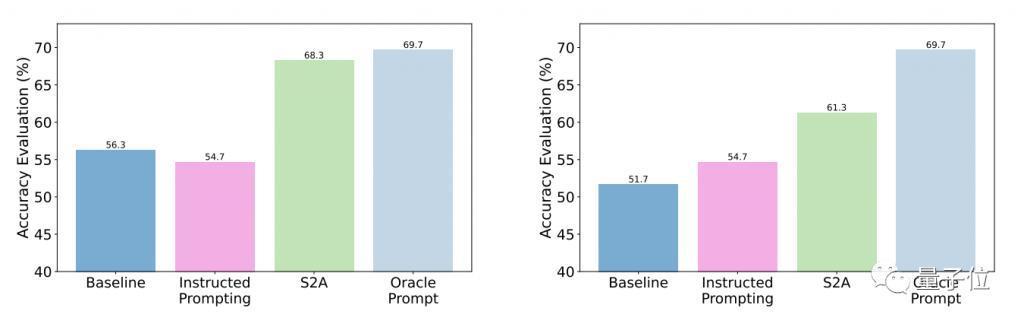
从反面看,只要将原始的干扰信息隔离,对 S2A 的其它调整都不会显著降低它的效果。
One More Thing
其实,通过注意力机制的调节改进模型表现一直是学界的一项热点话题。
比如前些时候推出的 " 最强 7B 开源模型 "Mistral,就利用了新的分组查询注意力模式。
谷歌的研究团队,也提出了 HyperAttention 注意力机制,解决的是长文本处理的复杂度问题。
……
而具体到 Meta 采用的 " 系统 2" 这种注意力模式,AI 教父 Bengio 更是指出:
从系统 1 向系统 2 的过渡,是走向 AGI 的必经之路。

用户对喜马拉雅的“一台设备一充值”的抱怨引发了网友的吐槽,认为这是一种花式割韭菜行为。
科技热搜 喜马拉雅 天猫精灵 手表 设备 韭菜 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-08-07

“遥遥领先”,一个华为热梗的走红
科技热搜 华为 芯片 余承东 华为mate 雷蒙 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-09-29

华为 Mate 60 Pro DXOMARK 影像测试结果出炉:总分157,位列排行榜第 1 名
科技热搜 华为mate google pixel oppo find x iphone 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-11-17

《繁花》:A先生最后一集终于露脸,为何是宝总的模样?
娱乐热点 导演 a股 李产 股市 陈真 新闻 资讯 直播 视频 美图 社区 本地 热点 2024-01-18

韩国女团大尺度造型惹争议,穿着令人费解,成员还有中国人
娱乐热点 造型 韩国 尺度 中国人 穿着 新闻 资讯 直播 视频 美图 社区 本地 热点 2024-02-04
 曾被卖出19万美元高价!这台初代iPhone太猛了
曾被卖出19万美元高价!这台初代iPhone太猛了
热门赛事

苹果首次允许欧盟用户从网站安装应用/雷军称对汽车价格战做好准备/微博上线热搜投诉入口
科技热搜 2024-03-13
在游戏里搞政治正确的幕后黑手,快被外国网友冲烂了。
科技热搜 2024-03-13
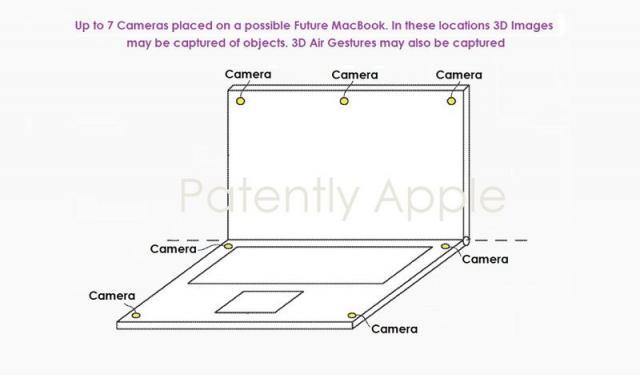
苹果 MacBook 新专利获批:可录制3D 图像/视频、追踪空中手势
科技热搜 2024-03-13
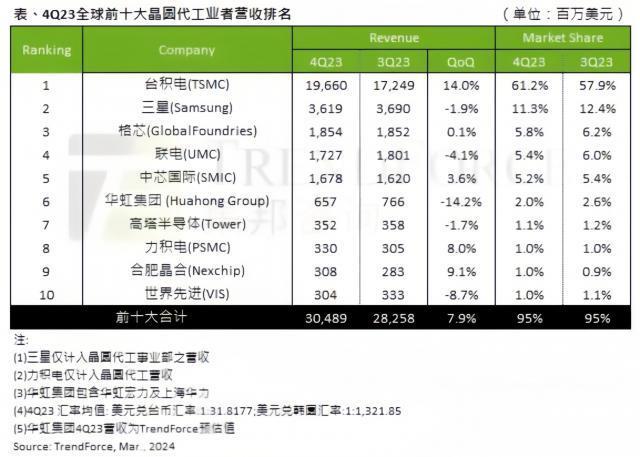
芯片代工营收排行榜公布:台积电独占六成,狂揽近200亿美元
科技热搜 2024-03-13
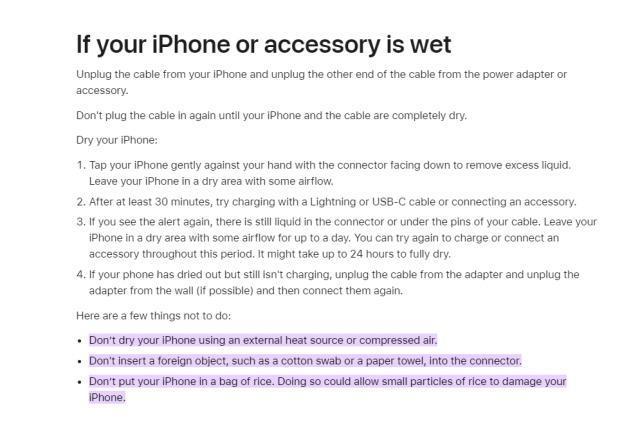
手机进水放米缸?苹果说这招没用。
科技热搜 2024-03-13

TikTok以“美式”反击“美式”
科技热搜 2024-03-13

消息称暴雪国服回归将在一个月内官宣,网易雷火营销/互娱运营
科技热搜 2024-03-13

从“放生”农夫山泉开始,这事算是彻底成互联网闹剧了。
科技热搜 2024-03-13
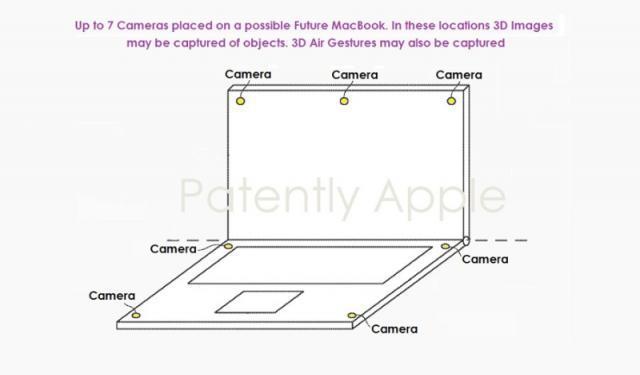
苹果获得适用于折叠设备和MacBook的摄像头系统专利
科技热搜 2024-03-13

消息称现代汽车将研发5纳米车用半导体,有望由三星、台积电代工
科技热搜 2024-03-13