吊打斯坦福炒虾机器人,GPT-4加持Alter3扮鬼玩吉他,Figure 01看视频学会煮咖啡
机器人的 ChatGPT 时刻,真来了!初创公司 Figure 自家机器人看了 10 小时视频,学会了煮咖啡。另一边,东京大学 GPT-4 加持的 Alter3 机器人,能够模仿人类做出任何动作。而人类只需发出自然语言指令即可,完全不需要编程!
机器人,本周果然迎来了 ChatGPT 时刻!
初创公司 Figure,就做出了一个能学人类煮咖啡的机器人。

就在昨天,Figure 创始人在社交平台上,提前预告了自家实验室取得的重大突破。
而东京大学则让 GPT-4 和仿人机器人 Alter3 相连。
人类只要给出自然语言命令,GPT-4 就能把这些指令转换为可执行的代码,让机器人模仿人类做出任何动作,包括弹吉他、自拍、扮鬼等等,甚至还能去电影院偷别人的爆米花。
心情很闲适,喝杯茶。

拿着吉他玩摇滚。

假装我是一条蛇。

来张自拍,像网红们一样摆出俏皮浮夸的表情。

在电影院边吃爆米花边看电影,忽然发现,自己吃的是别人的爆米花,顿时尴尬地笑起来。

看人类煮咖啡 10 小时,学会这项技能
名叫 Figure 01 的这个机器人,采用的是端到端的人工智能系统。
它只需观察人类煮咖啡的录像,就能在 10 小时内学会制作咖啡的技能。
这个机器人是通过神经网络来处理和分析视频数据的。通过观看录像,它能够学会人类的动作和手势,然后模仿这些动作,来学习制作咖啡的过程。
这个过程证明了,无需通过编程,机器人完全可以自主学习技能!
只要跟它说:Figure 01,你可以帮我做一杯咖啡吗?
它就会把咖啡胶囊放入机器内,用手按按钮,过不了多久,一杯香气四溢的咖啡就做好了!

这个过程中难能可贵的一点是,机器人能学习如何改正自己的错误,比如咖啡胶囊放得不对,它就会矫正自己。

Brett Adcock 解释了视频数据训练为何如此重要的原因。
之所以说这具有开创性意义,是因为如果你能获得某个应用的人类数据(如煮咖啡、叠衣服、仓库工作等),就可以在 Figure 01 的基础上对 AI 系统进行端到端的训练。
这是可以扩展到每种应用的一种方式。当机器人数量扩大时,从机器人群中收集更多数据,重新进行训练,机器人就能实现更好的性能。
值得一提的是,许多网友对机器人冲咖啡的速度表示惊讶。官方对此回应称,视频并没有加速。

东京大学的扮鬼机器人
而东京大学的这个人形机器人,之前就曾经因栩栩如生的「扮鬼」行为而出圈过。

东京大学的研究人员,把这个叫做 Alter3 的仿人机器人和 GPT-4 相连。
利用指令,它就可以完成一系列人类行为,比如弹吉他、自拍、扮鬼等等,甚至可以去电影院偷吃别人的爆米花。
这个过程中,LLM 将书面指令转换为可执行的代码,从而让机器人模仿出多种人类的动作。从视频效果上看,属实是吊打了最近风头正劲的斯坦福家务机器人。
也就是说,Alter3 之所以能戏精上身,将「鬼」模仿得如此出神入化,还是因为 GPT-4 的 prompt 给得好啊!
「0 创造恐惧的睁大眼睛的面部表情,张开嘴巴发出无声的尖叫」,
「1 迅速向后倾斜,仿佛被突然的幻影吓了一跳」,
「2 举起双手,在脸上挥舞,模仿幽灵般的动作」,
「3 张大嘴巴摇头,表现出恐惧的戏剧性反应」,
「4 将上半身从一侧移动到另一侧,仿佛被幽灵的存在所困扰」,
「5 双手握在胸前,表现出极度焦虑」,
「6 眼睛从一边瞟到另一边,仿佛目睹了一场诡异的活动」,
「7 先前倾,然后后倾,模仿鬼魂的漂浮动作」,
「8 慢慢回到休息位置,同时保持惊恐的表情」
通过代码,将人类动作映射到机器人身上
Alter3 是怎样使用 LLM 生成自发运动的呢?
具体过程,就是将 GPT-4 集成到了 Alter3 中,从而有效地将 GPT-4 与 Alter 的身体运动结合起来。
通常,低级机器人控制是依赖于硬件的,这超出了 LLM 语料库的范围,这给直接基于 LLM 的机器人控制带来了挑战。
不过,研究者在 Alter3 上,实现了突破——通过程序代码,他们将人类动作的语言表达映射到机器人的身体上,这就让直接控制变得可行了。
这种方法无需对每个身体部位进行显式编程,直接就可以让 Alter3 采用各种姿势,比如自拍或扮鬼,还能随着时间的推移生成一系列动作。
这充分证明了机器人的零样本学习能力。
甚至,口头反馈都可以调整机器人的姿势,无需微调。
比如,用 GPT-4 告诉机器人,「播放金属音乐」,它就接收到了信息,开始有模有样地弹起了电吉他,脑袋还跟着节奏晃动。

「0 创造一种强烈兴奋的面部表情,睁大眼睛,微微张开嘴巴,露出狂野的笑容」,
「1 积极地向前倾斜,仿佛准备潜入音乐中」,
「2 模仿左手握住吉他琴颈的动作」,
「3 用右手开始弹奏空气,仿佛在演奏沉重的即兴演奏」,
「4 有节奏地上下摇晃头部,模仿与金属音乐相关的甩头动作」,
「5 举起左手,仿佛伸手去弹更高的吉他音符,眼睛锁定在想象中的指板上」,
「6 用右手模仿戏剧性的吉他弹奏,仿佛击中有力的和弦」,
「7 右手在假想的吉他弦上慢慢扫过,模仿吉他独奏」,
「8 模仿将想象中的吉他砸在地板上的动作,体现金属音乐的狂野精神」,
「9 逐渐恢复到休息姿势,但保持激烈的面部表情,表现出挥之不去的兴奋」
LLM 把人类从迭代工作中解放出来
在 LLM 出现之前,为了让机器人模仿一个人的姿势,或者及假装一种行为,比如端茶、下棋,研究人员必须按照一定的顺序控制所有的 43 个轴。
这个过程中,需要人类研究员手动进行许多改进。
多亏了 LLM,现在人类研究者可以从迭代的工作中解放了出来。只要使用口头指令,就能控制 Alter3 的程序了。
研究者先后应用两个用自然语言编写的思维链协议,并不需要学习过程的迭代(也就是零样本学习)。
如图所示,研究人员使用了以下协议。
需要注意的是,GPT-4 是非确定性的(non-deterministic ) ,即使在 $$temperature=0.$$ 时也是如此。
因此,即使输入相同,也可以产生不同的运动模式。

使用口头指令控制 Alter3 人形机器人的程序。通过使用 Prompt1、2 输出 python 代码,从而使用自然语言控制 Alter3,这个架构是基于 CoT 的
语言反馈
Alter3 无法观察自己的世代对任何物理过程产生的影响,这在人类意义上是非常不自然的。
因此,Alter3 无法准确理解「手举多高」等细节,也就无法相应地改进自己的动作。
通过经验性地通过反馈来开发和利用外部记忆,Alter3 的身体模型可以与 GPT-4 集成,而无需更新其参数。
现在,Alter3 可以根据人类的语言反馈重写代码。
比如,用户建议「自拍时手臂抬高一点」,然后 Alter3 就可以将修改后的动作代码作为动作记忆存储在数据库中。
这样就能确保下次生成该动作时,机器人会使用经过改进和训练的动作。
通过这种反馈,机器人就积累了有关自己身体的信息,记忆就可以有效地充当一个身体图示。
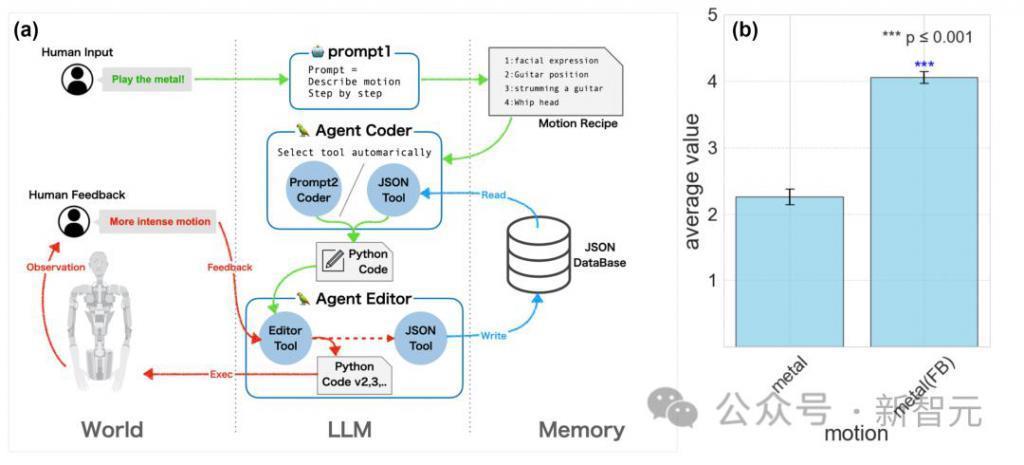
上图说明了 Alter3 中的语言反馈系统。
这个过程中,用户会提供语言反馈,来指导 Alter3 在每个运动分段中的调整,比如「将轴 16 设置为 255」或「更有力地移动手臂」。
在这个过程中,用户只需提供口头指令,无需重写任何代码,然后,Alter3 就会自动修改相应的代码。
一旦动作被完善,它就会被保存在一个带有描述性标签的 JSON 数据库中,例如「握住吉他」或「深思熟虑地敲击下巴」。
对于使用 prompt2 生成动作,JsonToolkit 有助于数据库搜索这些标签,LLM 会决定内存使用和新动作的创建。
textbf{ ( b ) } 比较有反馈和没有反馈的分数,有反馈的运动比没有反馈的运动得分更高。
结果
为了量化 GPT-4 生成动作的能力,研究人员评估了 9 种不同生成动作的视频,将其分为两类。
第一种情况是「即时手势」,包括「自拍」和「喝茶」等日常动作,以及「扮鬼」和「扮蛇」等模仿动作。
第二种情况是一段时间内的动作,包括更复杂的情景。就比如「在影院边吃爆米花边欣赏电影时,发现自己吃的其实是旁边人的爆米花」这样的尴尬情节,以及「在公园里慢跑时,世界似乎在讲述一个古老的生存故事,每一个脚步声都回荡着亘古不变的存在」这样的情感场景。
这些动作均由 GPT-4 生成。提示 1 的温度设置为 $0.7$,提示 2 的温度设置为 $0.5$。受试者($n=107$)是通过 Prolific 平台招募的。
他们观看了这些视频,并对 GPT-4(gpt-4-0314)的表达能力进行了评估(评估采用 5 级评分法,1 为最差)。
在对照组中,研究人员采用了 Alter3 的随机动作,并附加了由 GPT-4 生成的随机动作符号作为这些动作的标记。
这些贴有标记的对照视频被巧妙地纳入调查,其中 3 个被分散在向参与者展示的主要实验视频中。
为了确定对照视频与其他视频之间的评分是否存在显著差异,研究团队首先采用了弗里德曼检验法(Friedman test)。结果显示,不同视频之间的评分存在明显差异。使用奈曼尼检验(Nemenyi test)进行的进一步事后分析表明,虽然对照组视频之间的 p 值没有显著差异,但对照组与其他视频相比,p 值明显更小,这表明存在显著差异(见图)。
因此,与对照组相比,GPT-4 生成的动作评分明显更高。这表明,GPT-4 生成的 android 动作与对照组的感知不同。这一结果表明,该系统可以生成各种动作,从自拍、喝茶等日常动作到模仿鬼或蛇等非人类动作。
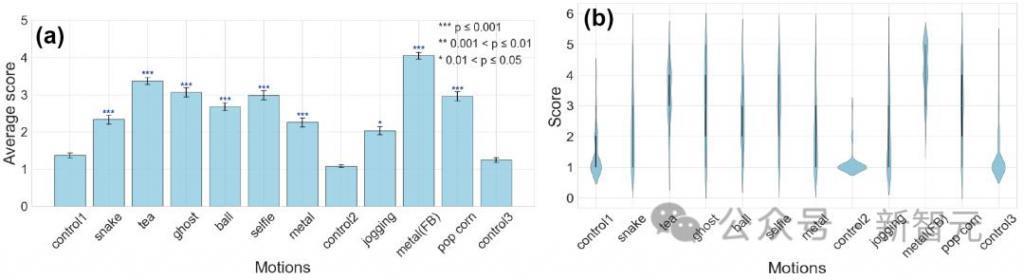
每个动作的平均评估分数
LLM 的训练包括一系列动作的语言表征。GPT-4 可以将这些表征准确地映射到 Alter3 的身体上。
最值得注意的是,Alter3 是一个与人类形态相同的仿人机器人,这使得 GPT-4 可以直接应用有关人类行为和动作的丰富知识。
此外,通过 Alter3,LLM 可以表达尴尬和喜悦等情绪。
即使在没有明确表达情绪的文本中,LLM 也能推断出适当的情绪,并在 Alter3 的表现中反映出来。这种语言和非语言交流的整合可以增强与人类进行更细致入微、更富同情心的互动的潜力。
LLM 可以推动具身智能
Alter3 如此高能的演示,回答了「具身智能对于 LLM 是否是必要的」这个问题。
首先,Alter3 不需要额外的训练就能完成许多动作。这意味着,训练 LLM 的数据集已经包含了动作描述。
也就是说,Alter3 可以实现零样本学习。
此外,它还能模仿鬼魂和动物(或模仿动物的人),这一点非常惊人。
甚至,它还能理解听到的对话内容,并通过面部表情和手势反映出故事是悲伤还是快乐。
至此,Alter3 通过 LLM 获得的加持,已经非常明显了。

用户对喜马拉雅的“一台设备一充值”的抱怨引发了网友的吐槽,认为这是一种花式割韭菜行为。
科技热搜 喜马拉雅 天猫精灵 手表 设备 韭菜 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-08-07

“遥遥领先”,一个华为热梗的走红
科技热搜 华为 芯片 余承东 华为mate 雷蒙 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-09-29

华为 Mate 60 Pro DXOMARK 影像测试结果出炉:总分157,位列排行榜第 1 名
科技热搜 华为mate google pixel oppo find x iphone 新闻 资讯 直播 视频 美图 社区 本地 热点 2023-11-17

韩国女团大尺度造型惹争议,穿着令人费解,成员还有中国人
娱乐热点 造型 韩国 尺度 中国人 穿着 新闻 资讯 直播 视频 美图 社区 本地 热点 2024-02-04

《繁花》:A先生最后一集终于露脸,为何是宝总的模样?
娱乐热点 导演 a股 李产 股市 陈真 新闻 资讯 直播 视频 美图 社区 本地 热点 2024-01-18
 曾被卖出19万美元高价!这台初代iPhone太猛了
曾被卖出19万美元高价!这台初代iPhone太猛了
热门赛事

苹果首次允许欧盟用户从网站安装应用/雷军称对汽车价格战做好准备/微博上线热搜投诉入口
科技热搜 2024-03-13
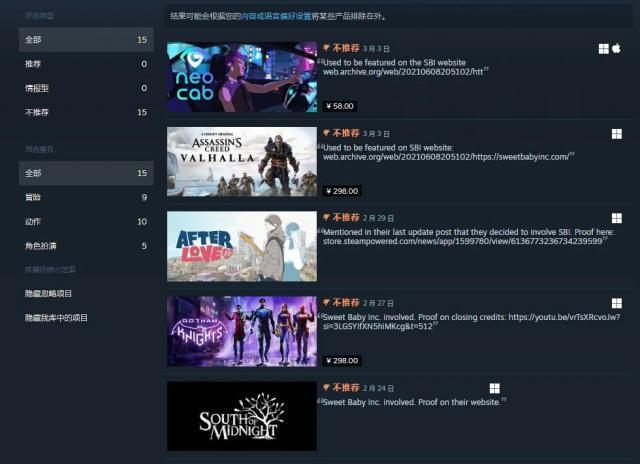
在游戏里搞政治正确的幕后黑手,快被外国网友冲烂了。
科技热搜 2024-03-13
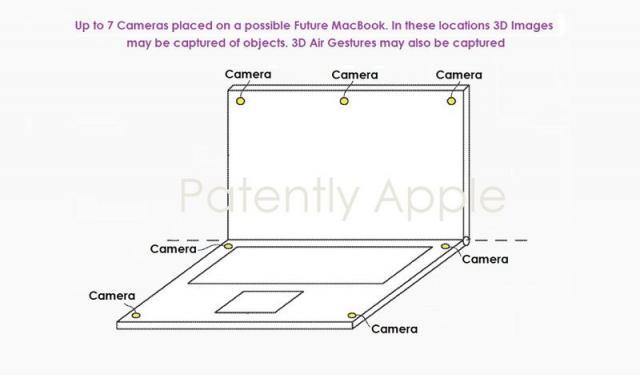
苹果 MacBook 新专利获批:可录制3D 图像/视频、追踪空中手势
科技热搜 2024-03-13
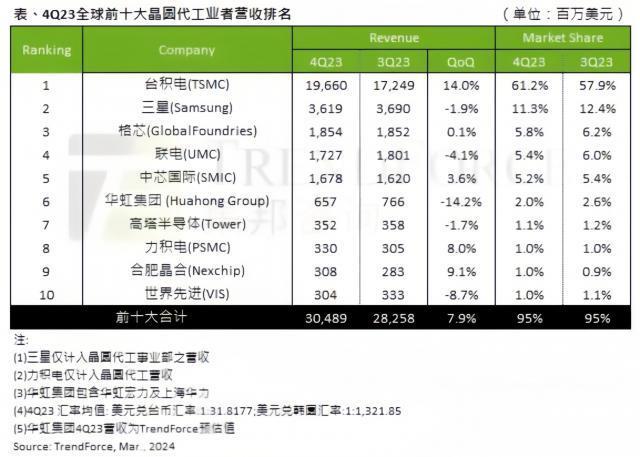
芯片代工营收排行榜公布:台积电独占六成,狂揽近200亿美元
科技热搜 2024-03-13
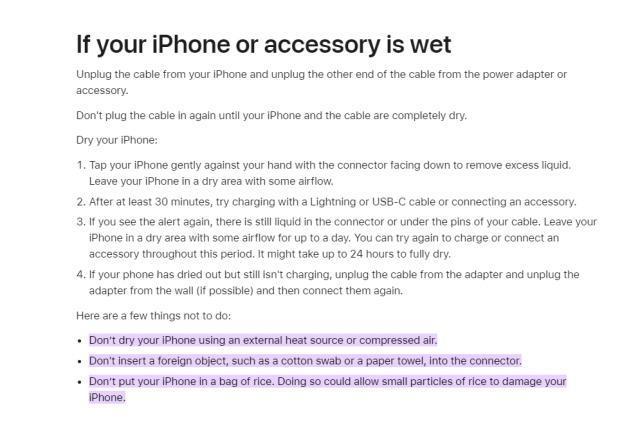
手机进水放米缸?苹果说这招没用。
科技热搜 2024-03-13

TikTok以“美式”反击“美式”
科技热搜 2024-03-13

消息称暴雪国服回归将在一个月内官宣,网易雷火营销/互娱运营
科技热搜 2024-03-13

从“放生”农夫山泉开始,这事算是彻底成互联网闹剧了。
科技热搜 2024-03-13
苹果获得适用于折叠设备和MacBook的摄像头系统专利
科技热搜 2024-03-13

消息称现代汽车将研发5纳米车用半导体,有望由三星、台积电代工
科技热搜 2024-03-13